

5个月前更新2764次阅读

1年前发布2764次阅读
1年前发布2764次阅读
1年前发布2763次阅读
1年前发布2763次阅读
5个月前更新2763次阅读

1年前发布2762次阅读
1年前发布2761次阅读
5个月前更新2761次阅读
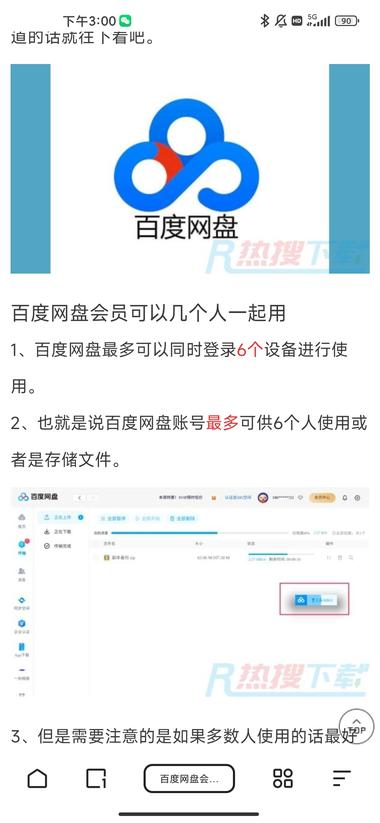
5个月前更新2761次阅读


1年前发布2761次阅读
1年前发布2760次阅读
1年前发布2760次阅读
5个月前更新2759次阅读
1年前发布2759次阅读
1年前发布2759次阅读
1年前发布2759次阅读
1年前发布2759次阅读
1年前发布2759次阅读
1年前发布2758次阅读